Table Of Content

This was important since controls were randomly selected from Minnesota State Driver's license list (this also included the list of individuals who have the State identity card). This makes them very rigid and not generalisable, as no extrapolation can be made about other outcomes like risk recurrence or future exposure threat. The modern epidemiologist’s arsenal for causal inference is well-suited to make transparent for case-control designs what assumptions are necessary or sufficient to endow the respective study results with a causal interpretation and, in turn, help resolve or prevent misunderstanding. Our approach may inform future research on different estimands, other variations of the case-control design or settings with additional complexities. Case-control designs are an important yet commonly misunderstood tool in the epidemiologist’s arsenal for causal inference. We reconsider classical concepts, assumptions and principles and explore when the results of case-control studies can be endowed a causal interpretation.
Case-control studies with matching
Case-control studies can be classified as retrospective (dealing with a past exposure) or prospective (dealing with an anticipated exposure), depending on when cases are identified in relation to the measurement of exposures. It grew in popularity in the 1950s following the publication of several seminal case-control studies that established a link between smoking and lung cancer. The first step in a case–control study is to identify the cases through application of explicitly defined inclusion and exclusion criteria. The case-selection process and the data sources from which cases were selected should be described in detail, especially if cases are from a variety of sources, such as hospital and community-based sources.
Enhancing Healthcare Team Outcomes
The 1167 cases - individuals with invasive cutaneous melanoma – were selected from Minnesota Cancer Surveillance System. The 1101 controls were selected randomly from Minnesota State Driver's License list; they were matched for age (+/- 5 years) and sex. In their landmark study, Doll and Hill (1950) evaluated the association between smoking and lung cancer. A case-control study differs from a cross-sectional study because case-control studies are naturally retrospective in nature, looking backward in time to identify exposures that may have occurred before the development of the disease. Since we considered arbitrary intervals between time points and because, in real-world studies, time is never measured in a truly continuous fashion, this does not represent an important limitation for practical purposes. It is however important to note that the intervals between interventions and outcome assessments (in a target trial) are an intrinsic part of the estimand that lies at the start of investigation.
Prosaposin variants in sporadic, familial, and early-onset Parkinson's disease: a Taiwanese case–control study and ... - Nature.com
Prosaposin variants in sporadic, familial, and early-onset Parkinson's disease: a Taiwanese case–control study and ....
Posted: Fri, 26 Jan 2024 08:00:00 GMT [source]
Additional Points in A Case-Control Study
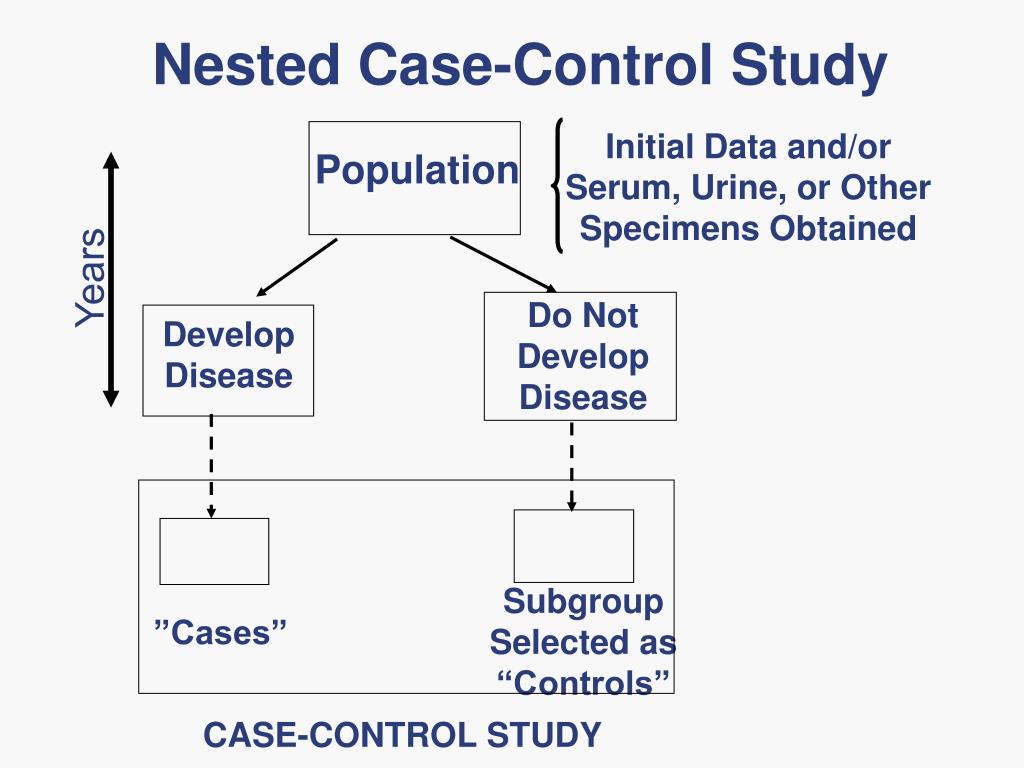
Case-control studies are beneficial for an initial investigation of a suspected risk factor for a condition. The information obtained from cross-sectional studies then enables researchers to conduct further data analyses to explore any relationships in more depth. A case-control study is a research method where two groups of people are compared – those with the condition (cases) and those without (controls). By looking at their past, researchers try to identify what factors might have contributed to the condition in the ‘case’ group. There is a suspicion that zinc oxide, the white non-absorbent sunscreen traditionally worn by lifeguards is more effective at preventing sunburns that lead to skin cancer than absorbent sunscreen lotions. A case-control study was conducted to investigate if exposure to zinc oxide is a more effective skin cancer prevention measure.
What Is a Case-Control Study? Definition & Examples
The case-control family of study designs is an important yet often misunderstood tool for identifying causal relations [12–15]. The conditions under which identifiability is to be sought for practical purposes may well include more constraints or obstacles to causal inference, such as additional missingness (e.g., outcome censoring) and measurement error, than we have considered here. While some of our results assume that hazards or hazard ratios remain constant over time, in many cases these are likely time-varying [10, 11]. There are also more case-control designs (e.g., the case-crossover design) to consider.
Set-up of underlying cohort study
Household environment and genetic factors may be accounted for by enrolling siblings as controls. Even though matching is used to increase the efficiency in case-control studies, it may have its own problems. It may be difficult to fine the exact matching control for the study; we may have to screen many potential enrollees before we are able to recruit one control for each case recruited. For example, in the above mentioned metabolic syndrome and psoriasis, we can decide that for each case enrolled in the study, we will enroll a control that is matched for sex and age (+/- 2 years). Thus, if 40 year male patient with psoriasis is enrolled for the study as a case, we will enroll a year male patient without psoriasis (and who will not be excluded for other reason) as controls. In fact, Wacholder and colleagues have extensively discussed aspects of design of case control studies and selection of controls in their article.
The risk of melanoma also increased with increase in years of use, hours of use, and sessions. Keep in mind that by definition the case group is chosen because they already possess the attribute of interest. The point of the control group is to facilitate investigation, e.g., studying whether the case group systematically exhibits that attribute more than the control group does.
About this article
The methodologic rigour of cohort and case–control studies evaluating drug–outcome associations is advancing, and approaches are being developed and refined that limit the generation of misleading study results. Indeed, both RCTs and observational studies are necessary, and neither is sufficient to learn about the totality of drug effects in the population. They are particularly appropriate for (1) investigating outbreaks, and (2) studying rare diseases or outcomes. An example of (2) would be a study of risk factors for uveal melanoma, or corneal ulcers. Since case-control studies start with people known to have the outcome (rather than starting with a population free of disease and waiting to see who develops it) it is possible to enroll a sufficient number of patients with a rare disease. The practical value of producing rapid results or investigating rare outcomes may outweigh the limitations of case-control studies.
One may start with a group of people with a known exposure and a comparison group (‘control group’) without the exposure and follow them through time to see what outcomes result, but this does not constitute a case-control study. Although controls must be like the cases in many ways, it is possible to over-match. Also, once a matching variable has been selected, it is not possible to analyse it as a risk factor. By definition, a case-control study is always retrospective because it starts with an outcome then traces back to investigate exposures.
Since the OR is greater than 1, the outcome is more likely in those exposed (those who are diagnosed with metabolic syndrome) compared with those who are not exposed (those who do are not diagnosed with metabolic syndrome). However, we will require confidence intervals to comment on further interpretation of the OR (This will be discussed in detail in the biostatistics section). They can be particularly useful when we are interested in trying to ensure that some of the measurable and non-measurable confounders are relatively equally distributed in cases and controls (such as home environment, socio-economic status, or genetic factors). The next important point in designing a case-control study is the selection of control patients.
In causal inference, it is important that the causal question of interest is unambiguously articulated [1]. The causal question should dictate, and therefore be at the start of, investigation. When the target causal quantity, the estimand, is made explicit, one can start to question how it relates to the available data distribution and, as such, form a basis for estimation with finite samples from this distribution.







No comments:
Post a Comment